Auto-Scaling Jenkins with Kubernetes
by John Turner
Posted on February 09, 2017
Kubernetes, Docker, Jenkins
Jenkins is a great piece of software (ok, it has problems but I couldn’t imagine software development without it). But one of the challenges with maintaining a Jenkins cluster is capacity management. It’s fairly typical to start out with a single master instance. Over time the number and size of Jenkins jobs increases placing more and more demand on the server. The first fix people apply when this happens is to vertically scale the Jenkins server (In fact I recently interviewed for a position and was told their Jenkins server hardware had 40 cores and 512GB of RAM). Some of the problems with scaling vertically include:
- Cost per unit of scale increases with the size of the hardware.
- Complex software configuration required to support a large variety of job types.
- Greater risk of ‘noisy neighbours’ impacting:
- job performance.
- server stability.
The alternatives to vertically scaling the Jenkins master are to:
- Deploy multiple Jenkins masters allocated:
- per environment.
- per organisational unit.
- per product line.
- Deploy statically provisioned Jenkins slaves.
- Deploy dynamicaly provisioned Jenkins slaves.
- Deploy multiple Jenkins masters with statically or dynamically provisioned Jenkins slaves.
There are a few things to consider when choosing how to scale your Jenkins infrastructure. If you choose to deploy multiple master you should have an efficient and effective way to manage them. At a minimum, you should use configuration management or orchestration tooling to manage the lifecycle of the instances themselves. You should also consider similar for managing plugins, jobs etc. In the past I have had great success using tools like Chef and Job DSL to manage build infrastructure.
If you choose to use slaves, consider if you should provision bloated slaves capable of performing any build Job or if you should provision specialized slaves.
Time to press on and deploy an auto-scaling Jenkins cluster with Kubernetes.
First thing we’ll do is to deploy a Jenkins master. If you haven’t already done this you can follow the instructions in the previous posts Deploying Jenkins with Kubernetes and Adding Persistent Volumes to Jenkins with Kubernetes. We do however need to make one change to the jenkins-deployment.yaml file so that the JNLP port is exposed.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: jenkins
spec:
replicas: 1
template:
metadata:
labels:
app: jenkins
spec:
containers:
- name: jenkins
image: jenkins:2.32.2
ports:
- name: http-port
containerPort: 8080
- name: jnlp-port
containerPort: 50000
volumeMounts:
- name: jenkins-home
mountPath: /var/jenkins_home
volumes:
- name: jenkins-home
emptyDir: {}With the Jenkins master deployed we next configure Jenkins to auto-scale slave nodes.
As described in Adding Persistent Volumes to Jenkins with Kubernetes you should enter the administrator password, install suggested plugins and create an administrator user.
For Jenkins to dynamically provision Jenkins slaves as Kubernetes Pods, the Kubernetes Plugin is required. To install the Kubernetes Plugin navigate to Manage Jenkins > Manage Plugins > Available, search for the Kubernetes Plugin, check the install checkbox and press Download now and install after restart.
With the Kubernetes plugin installed it must be configured by navigating to Manage Jenkins > Configure System and scrolling to the Cloud section. First we configure the Kubernetes Section as below:
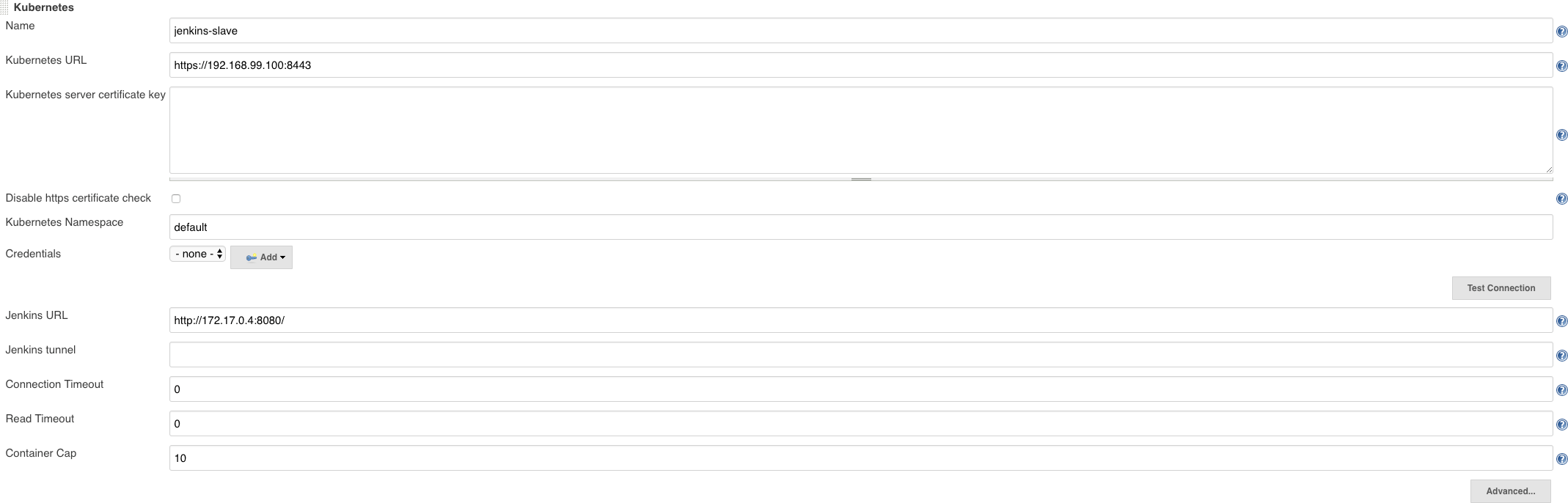
To obtain the Kubernetes URL you should invoke:
$ kubectl cluster-info | grep master
Kubernetes master is running at https://192.168.99.100:8443To obtain the Jenkins URL you first need to obtain the pod name of the Jenkins master:
$ kubectl get pods | grep ^jenkins
jenkins-2559287856-5p145 1/1 Running 0 54mAnd then obtain the IP address of the pod:
$ kubectl describe pod jenkins-2559287856-5p145 | grep IP:
IP: 172.17.0.4With these configuration entries the Jenkins Kubernetes plugin can interact with the Kubernetes API server. Next we need to configure the pod template and container for the slave so that the plugin can provision a pod.
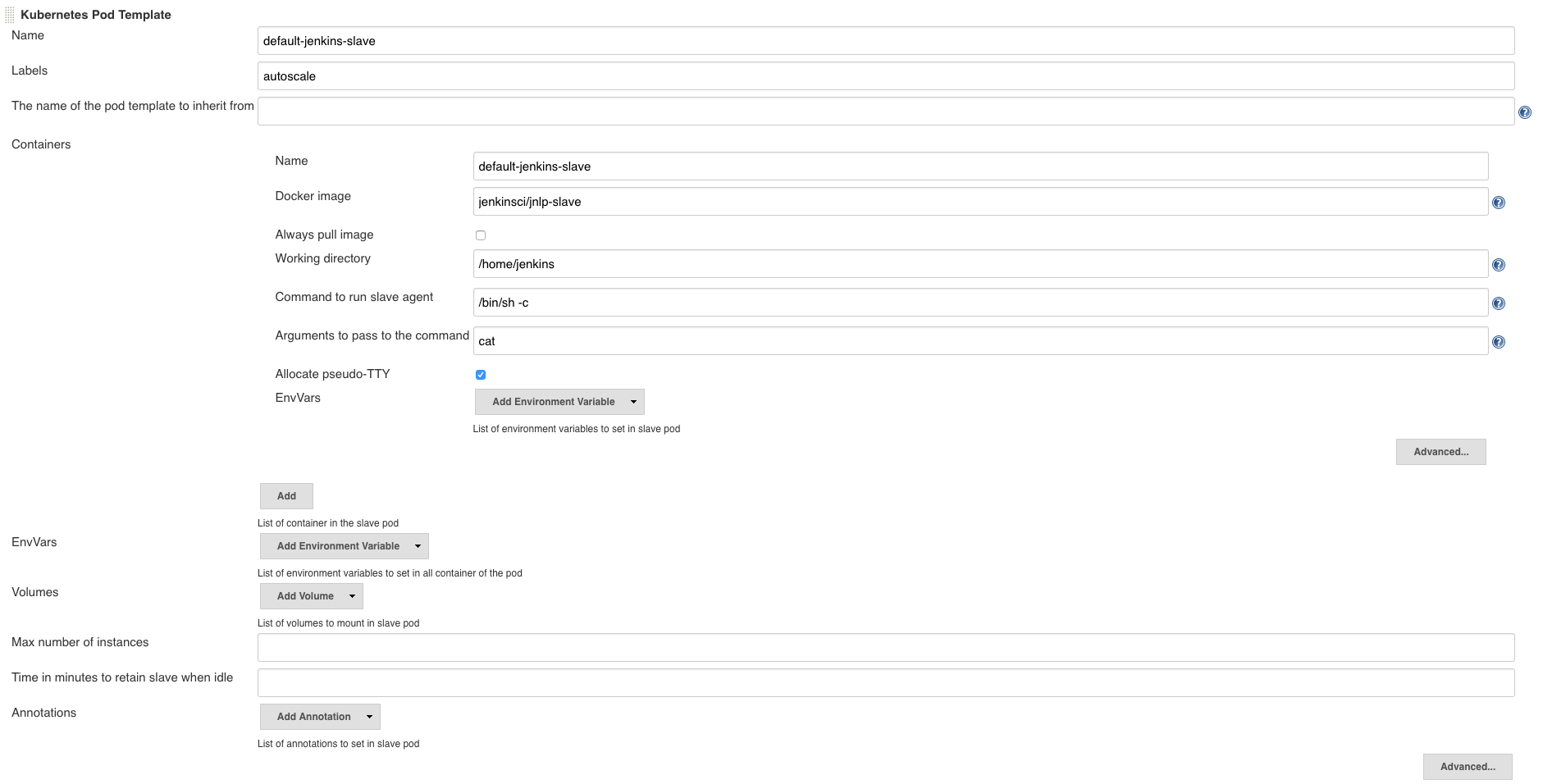
A few things to note here:
- The docker image is the standard Jenkins slave image from Jenkins CI. It is probable that you will want to use your own images for Jenkins slaves.
- Being able to specify labels and docker images makes it possible to use specialized Jenkins slaves.
- The working directory is specific to the docker image.
If you’ve followed along so far you should be ready to create a job to test our autoscaling behavior. Go ahead and create a new Freestyle project. You will need to set the Label Expression field to match that specified in the Pod Template configuration. I’ve also created an Execute shell build step.

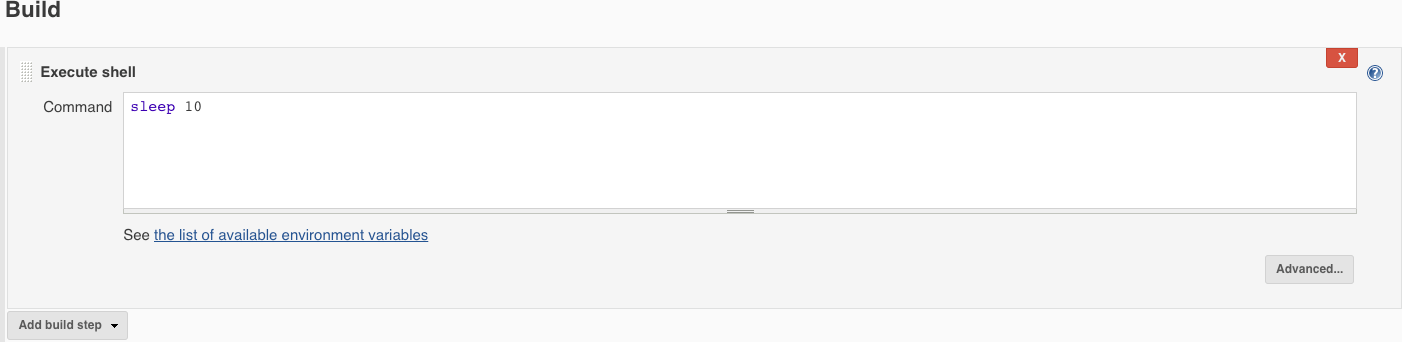
You are now ready to build the job. Before doing that you should watch the Kubernetes Pods. Do this by installing watch (brew install watch) and executing the watch as follows:
$ watch kubectl get pod
Every 2.0s: kubectl get pod Homer.local: Thu Feb 9 17:06:24 2017
NAME READY STATUS RESTARTS AGE
default-jenkins-slave-11f26675ac49 2/2 Running 0 4s
jenkins-2559287856-5p145 1/1 Running 0 1hkubectl get pods -wThen as your build job executes you can watch the pod being created and destroyed.
Over the past few days I’ve:
- given a high level overview of Kubernetes,
- demonstrated how to deploy Jenkins,
- how to add persistent volumes so that the Jenkins data is durable across container restarts
- and how to configure an autoscaling Jenkins cluster.
Next, I’d like to build a bespoke Jenkins image that avoids having to go through the Jenkins initialization steps. As always, feedback very welcome.