Kubernetes Fundamentals
by John Turner
Posted on February 06, 2017
Kubernetes, Docker
Over the last few years, I’ve been watching with interest the container space in general and specifically the level of interest being generated by the various orchestration options available. I still remain quite sceptical about the ease with which most organizations could effectively adopt containers (and the resulting changes to development and operational practices). However, I do believe that systems like Mesos and Kubernetes will eventually become default deployment environments for all but a few. With that in mind, I’ve decided to dive into Kubernetes to get a better understanding of the opportunities and challenges ahead.
![]()
Kubernetes is a system that has emerged from Google for automating deployment, scaling and management of containerized applications. It is one of a number of orchestration tools whose emergence has coincided with the increasing popularity and maturity of container runtimes such as Docker and rkt. Other orchestration tools include Docker Swarm, Fleet and Mesos.
Each of the previously mentioned orchestration tools incorporate a number of concepts, some of which are very similar and others which are quite distinctive. This can make it quite challenging when you come to learn about one or other (and even more so when you come to compare them). In this post I will briefly describe some of the key concepts you should understand when starting out with Kubernetes.
Kubernetes Cluster

Kubernetes is a distributed system which consists of a number of connected virtual or physical machines. At a minimum a Kubernetes cluster consists of two machines; one Master and one Node. As of v1.5.1, Kubernetes state support for clusters of up to 2000 nodes with the following stipulations:
- No more than 2000 nodes
- No more than 60,000 total pods
- No more than 120,000 total containers
- No more than 100 pods per node
Kubernetes environments can of course grow beyond this scale and that is achieved through cluster federation. Federation facilitates:
- Keeping resources in multiple clusters in sync.
- Exposing DNS and loadbalancer information across clusters.
Kubernetes Master
The Master is responsible for coordinating all activities in the cluster. This includes deploying applications, maintaining desired state (e.g. in the event of failure), scaling applications and rolling out updates. Cluster administration is performed by invoking an API exposed by the Master either directly (if you are building tools), via the Kubernetes command line interface or the Kubernetes dashboard. The Nodes within the cluster also interact with the Master via the same API.
In a non-critical environment there may be a single master node but in environments that need to be resilient to failure multiple master nodes are required. Within the Master node etcd is used for data storage so when using multiple masters it is necessary to cluster etcd so that data is replicated across the Master nodes. It is also necessary to place a loadbalancer in front of the API server running on each Master node.
The Kubernetes Master contains a number of components for which there may only be a single instance active within the cluster. These are the scheduler and the controller-manager. For these components a leader election process occurs to ensure a single instance running at any one time. In the event of failure a new leader will be elected from the available nodes.
Kubernetes Node
The Kubernetes Node is the workhorse of the cluster. A Node is managed by the Master and can be either a virtual or physical machine. Within each node exists an operating system, a container runtime (Docker is supported with experimental support for rkt), a proxy server (kube-proxy) and a node agent (kubelet).
The kubelet executes instructions issued by the master node and provides periodic updates of node and pod health. Those instructions include locally provisioning pod resources such as containers, volumes etc. The kubelet also enables log retrieval.
The kube-proxy is a simple network proxy and loadbalancer for services on the Node.
The Node runs a process supervisor service that restarts the container runtime or kubelet in the case of failure.
Deployment

A Deployment is a logical component that describes the desired state of Pods and Replica Sets. Use of a Deployment allows Kubernetes to perform richer orchestration as opposed to fine grained transactional actions. Examples of this include:
- Scaling a deployment either explicitly or based on CPU utilization of existing Pods.
- Performing rolling updates.
- Rolling back an update to a previous version.
Given that a deployment specifies the desired state, all the detail relating to how Kubernetes converges the deployment is abstracted. This makes using deployments easier to learn than the alternative of explicitly writing instructions to achieve the desired state. It also means that Kubernetes can reason about the current state and act accordingly.
Pod
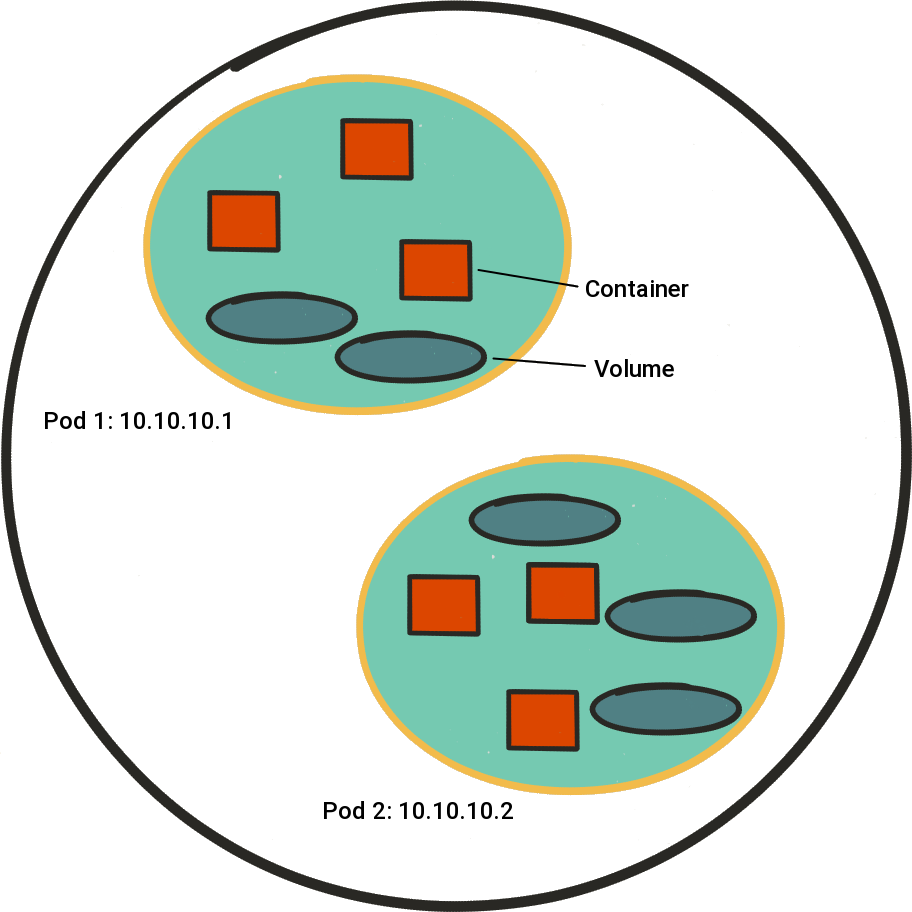
A Pod exists within a single Node and can consist of a number of application containers with associated volumes. Each Pod is allocated a dedicated IP address upon creation. Containers and Volumes cannot be created individually and must be created within a Pod.
Pods have no orchestrated behavior and so if you chose to deploy Pods outside a Deployment or Replication Controller you will not have any auto-recovery, auto-scaling, update or rollback behaviors.
Services
A Service provides a stable name and address for a set of Pods. Each Service gets it’s own virtual IP address which remains constant across Pod failure and recovery (Pods themselves will be assigned a new IP address).
A Service is associated with Pods via a selector which matches against labels assigned to the Pods during creation. Traffic is then routed from the Service to the Pods.
Now I’ve a high level understanding of the key Kubernetes concepts I’m in a better place to dive into some specifics.