Lifecycle of a Continuous Delivery Pipeline
by John Turner
Posted on February 28, 2014
Continuous Delivery
Following on from my recent post, PaaS and Continuous Delivery - My 12 Month Journey, I wanted to delve deeper into the lifecycle of the staged delivery pipeline. When working in a heterogeneous technology environment there exists a requirement to support multiple language runtimes, application containers, message brokers, storage engines etc. For this reason, the lifecycle must be abstracted from the implementation technology.
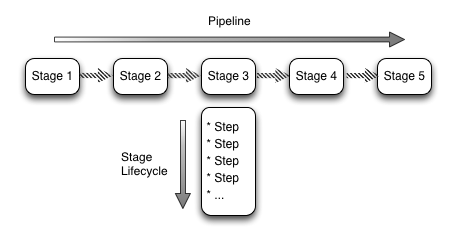
For the remainder of this post I will propose a number of stages and the steps within each stage.
Introducing the Stages
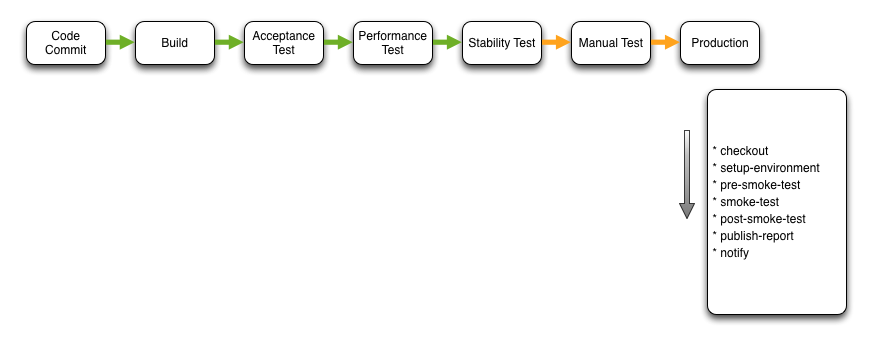
From the abstract, it’s straightforward to identify pipeline stages from your current release process. What you will discover though, is that you may have to rethink your pipeline to production to fit into this automated process. An example of this is depicted below.
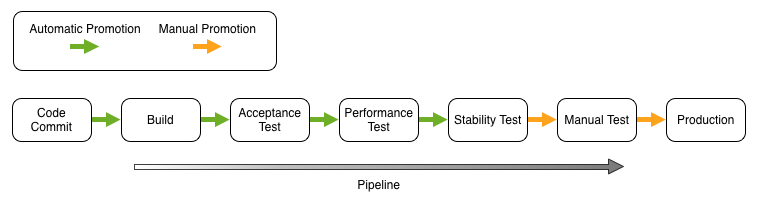
Before digging into the detail of each stage, it’s important to understand how some of the guiding principles used to design the pipeline stages. They were:
- Stages to the left should provide richer feedback to the development team than stages to the right.
- Automatic stage transitions should be built from left to right so that there are fewer queues within the system.
The significant change from a manual process is the introduction of automated acceptance testing and Acceptance Test Driven Development (ATDD). As a result acceptance testing migrated left in the lifecycle.
Given the level of automation, I introduce two stages that are often missing within a manual process. Those are the Performance Test and the Stability Test stages. I can already hear you gasp at the suggestion that performance testing would not exist prior to this automation. Naturally, manual performance testing should be performed within both a manual and automated release process. The Performance Test stage performs performance trend analysis as opposed to absolute performance analysis (I’ll go into this later).
Similarly to the performance testing, operational testing did exist prior to automation, it just existed in a very different guise.
An obvious enhancement to the process illustrated in figure 2 would be to fork after the build stage to run acceptance test, performance test and stability testing in parallel. We’ll omit this optimisation for simplicity.
I’ll now describe each stage in more detail.
Code Commit
The code commit stage is triggered by a code check-in to the SCM repository. The purpose of this stage is to provide immediate feedback to the developer by compiling the code and running unit tests. If development is not in pairs it’s assumed that a code review has also occurred prior to committing to the repository.
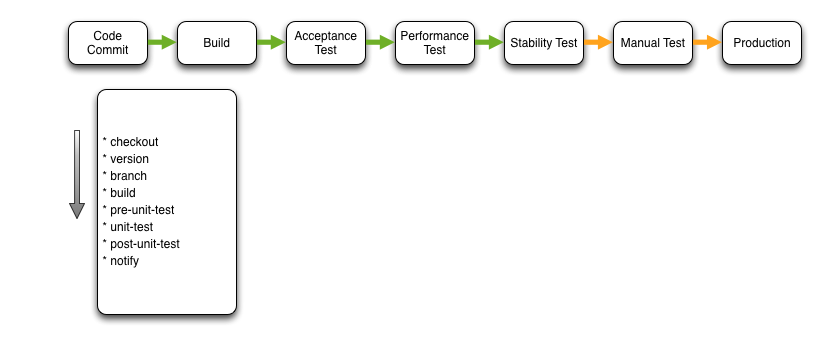
The Checkout step is self-explanatory and simply checks out the repository locally on the CI server.
Version updates the local source with the build number. Each execution of the pipeline can be identified by a unique (incrementing) build number that forms part of the semantic versioning scheme (i.e. major.minor.build).
The purpose of the Branch step is to isolate the pipeline instance from other instances. The repository is ‘branched’ so that each pipeline operates on a separate copy of the code base.
The Build step builds the software artefacts. The actual act of building may be invoked by triggering a Maven, Gradle, Rake etc. task. Because the pipeline is not implementation specific the choice is only limited by the support provided by the CI server.
Pre Unit Test invokes a task in the build system to facilitate preparation for unit testing. Typically this is an empty step as there are normally no setup tasks for unit tests. The Unit Test step is rather self-explanatory. A task is invoked in the build system to trigger unit testing. Similarly to pre-unit-test, the Post Unit Test step invokes a task in the build system to facilitate clean up after unit testing. Typically this is an empty step as there are normally no teardown tasks for unit tests.
Finally, the Notify step notifies possible culprits of build failure or on success, invokes the next stage on the pipeline.
Build
The main purpose of the build stage is to create potentially releasable software artefacts that become the ‘golden copy’.
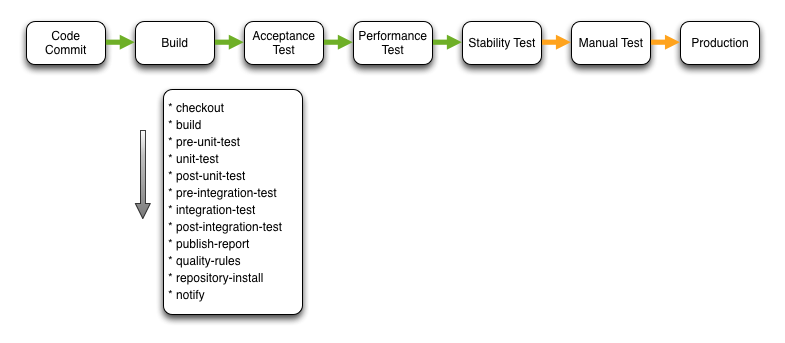
Checkout checks out the source from the local repository (as opposed to the remote or origin). The build, pre-unit-test, unit-test and post-unit-test steps are repeated.
Pre Integration Test and Post Integration Test invoke the build setup and teardown before and after the Integration Test step. It’s important to note that these integration tests are executed on a hermetic server so as to ensure the feedback is fast.
Publish Report exports an array of test result reports that are supplemented by the reports generated during the execution of the Quality Rules.
At this point you can be reasonably confident that the software artefacts are viable release candidates. To ensure that the exact same artefacts under test are those that are pushed to production they are uploaded to a repository during the Repository Install.
Acceptance Test
This stage executes the automated acceptance test suite against a production like (scaled down) environment.
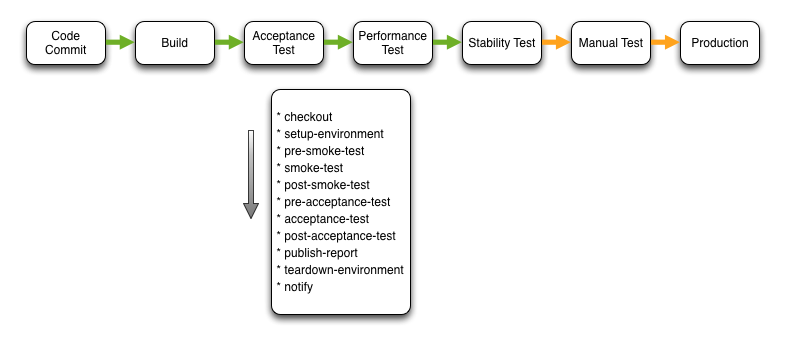
Following Checkout, the CI server interacts with the PaaS to perform the Setup Environment step. During this step the PaaS provisions the infrastructure required by the application and overlays software and configuration as per the application blueprint. On completion of the provisioning activity, the environment contextual information (IP addresses etc.) is exported so that it is available within the subsequent test steps.
Pre Smoke Test and Post Smoke Test invoke the build setup and teardown before and after the Smoke Test step. Smoke tests may perform read only and synthetic transactions that verify the function of the system but do not modify state. These smoke tests are invoked during every step that provisions an application environment.
The Pre Acceptance Test, Acceptance Test and Post Acceptance Test steps function similar to the other test steps. The same is true for the Publish Report step. Clearly the reports published are related to the acceptance tests. Thucydides is an example of the type of testing and reporting that can be performed during this stage.
On completion of the acceptance test execution the Teardown Environment step un-provisions the test environment. An important thing to note is that all compute and storage is un-provisioned so if there is valuable information stored locally on the provisioned infrastructure it should be streamed to an archive. As I mentioned briefly in my previous post, APM and log aggregation tools (such as Logstash) work really well for this purpose.
Performance Test
The Performance Test stage provisions an application environment and executes a suite of performance tests. Because the environment provisioned is a scaled down ‘production like’ environment I view this as a performance trend stage. What is asserted is that the variation in performance from previous builds is acceptable. This is not the same as testing for absolute performance.
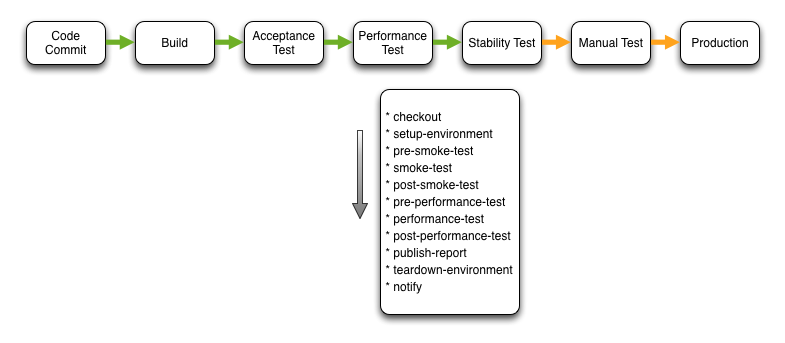
I’m not going to describe each step within this stage as the steps are either the same or similar to those within previous stages.
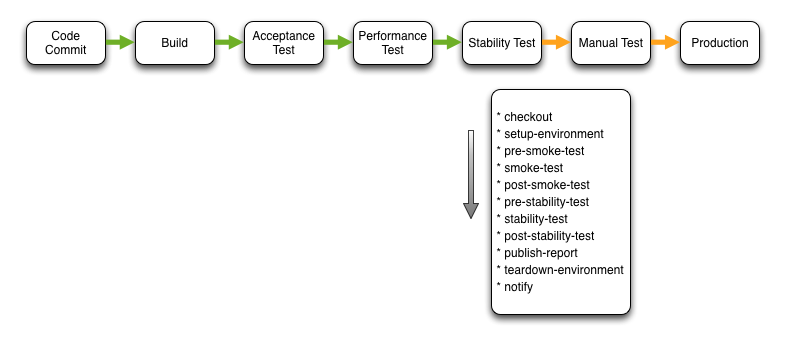
Stability Test
This Simian Army inspired stage performs the exact same steps and activities as the acceptance test stage. The intent is to execute the automated acceptance test suite during the Stability Test step. The difference being that during the execution of the acceptance tests, the orchestration engine executes failure scenarios. Failure scenarios can include node failure, resource starvation etc.
Manual Test
On passing the previous stages focused on automated testing of the application, a manual decision can be taken to promote a potentially releasable artefact to a manual test environment. This decision is typically based on the new feature set available in the release.
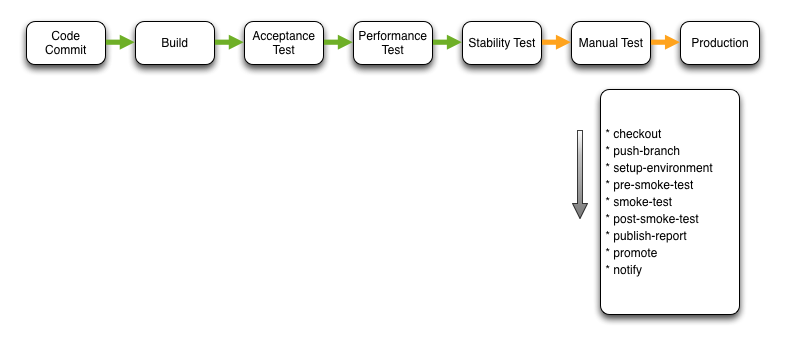
The Push Branch step pushes the local branch to the remote SCM repository.
The Publish Report step typically pushes release requests to change management systems (such as Remedy etc.) as well as automatically compiling required release documentation and collating audit information etc. As a result, if the company you work for employs a release co-ordinator they can be presented with all relevant information with no manual documentation effort.
The Promote step promotes the software artefacts stored in the artefact repository from a ‘potential release candidates’ repository to a ‘release candidates’ repository. This indicates that if there is business value to releasing this version of the software that you can be assured that it has past all quality and audit procedures.
Production
At last, Production
Often, this stage is more complex that illustrated and comprises of multiple segments of production and a staged release. Nevertheless, I’ve described a fairly robust continuous delivery pipeline lifecycle that goes beyond what many practice today. I strongly believe this capability provides competitive advantage for both technology-enabled and technology-led business domains. If you are not working to release value to production quicker you can be sure your competitors are…and they are going to eat your lunch!!
A Word on Implementation
There are obviously lots of implementation details I could discuss but I wanted to highlight just one. This type of build system has lots of moving parts and can become quite complex very quickly if you are not careful. I would advise that you use the same provisioning and configuration management tools that you use for your applications to manage your build environment…and I mean everything in your build environment.