IaaS: Making a Case for Infrastructure as a Service
by John Turner
Posted on July 23, 2013
IaaS
Today, there is a lot of discussion focussed on cloud computing and infrastructure as a service (IaaS) but this is still an area that is little understood by many in the enterprise. It is of no surprise that enterprises are slow to adopt and adapt to new concepts and technologies as their sheer size creates inertia. Marc Shedroff, VP of Samsung Open Innovation Center, provides us with some insight into this phenomenon in his article ‘Why Don’t Big Companies Innovate More?’.
In the not too distant past, most enterprises followed an extensive and involved process to provision their infrastructure requirements. This might have looked something like this:
- Compile infrastructure requirements
- Submit to infrastructure team
- Obtain vendor quote(s)
- Sign-off spend
- Raise PO
- Install and configure infrastructure
- Release to customer
The reality was that you would be considered fortunate if you only needed to wait for six weeks from submitting a requirement until you could utilise the requested infrastructure. There were of course other problems. Once a requirement had been submitted it was very difficult to modify. If it was possible to modify it, normally it would ‘reset the clock’ for the lead time SLA. Once delivered it was difficult and expensive to modify the hardware configuration. All this ceremony was inefficient and the result was often under utilised infrastructure as there was little opportunity for sharing. Because each requirement was considered in isolation, the result was a heterogeneous data centre that increased operational complexity and costs.
The solution to this problem was to virtualize the data centre. This gave us a homogeneous data centre that reduced complexity and operational costs. Complementary tool-sets made it easy to manage capacity and provision virtual infrastructure. You only pay for infrastructure you use, there is more flexibility to modify requirements and provisioning can be done in minutes. So why are we still waiting for infrastructure??

The reality for many is that virtual infrastructure is often treated like physical infrastructure. From the consumers perspective, the same ceremony is associated with provisioning. It’s still difficult to change in flight requirements or to modify an existing configuration. This incentivises customers to behave in a sub optimal fashion. For example, rather than release compute and storage resources when done, these resources are retained and repurposed eventually. Where is the promise of better utilisation gone?
So our friends at Amazon started to make this whole IaaS thing popular. But why is it catching on in the enterprise? Well lets see.
The service piece of Infrastructure as a Service is very significant. You are the customer again and you are provided infrastructure as a service. You are not given whats available or what people think you want. You are given exactly what you asked for and when you asked for it. Guess what? You are only going to pay for what you use and when you’re done, give it back. Made a mistake? No problem, just ask for it again and we have it on the shelf. This lets us do lots of cool stuff like platform as a service, orchestration etc.
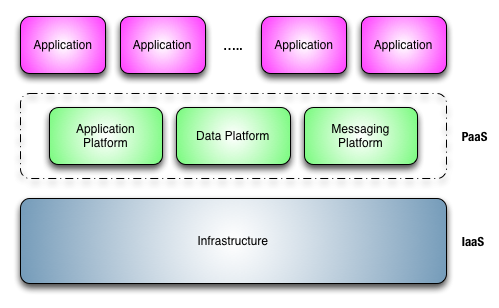
IaaS provides a clear boundary of responsibilities. Infrastructure people can now focus on doing some cool infrastructure stuff like elastic load balancing and cost based payload placement. Whoa that’s really interesting stuff. I don’t have to spend my time provisioning virtual machines any more. Well that’s the infrastructure folks happy.
And the application folks don’t have to wait for infrastructure to be provisioned. I can actually spend my time writing code and solving business problems. No more waiting around. You know we can start to do some cool stuff as well like provisioning on demand, dynamic scaling and auto recovery. Well the application folks are happy.
I think the business folks are going to be over the moon because we’ve just butchered lead times for project initiation and cut operational costs. Really? How? Lets look at the short end of the wedge and how we save on infrastructure.

Above we see a timeline of the infrastructure utilisation of a fictional application (Application 1). As with most applications, it varies significantly day by day.
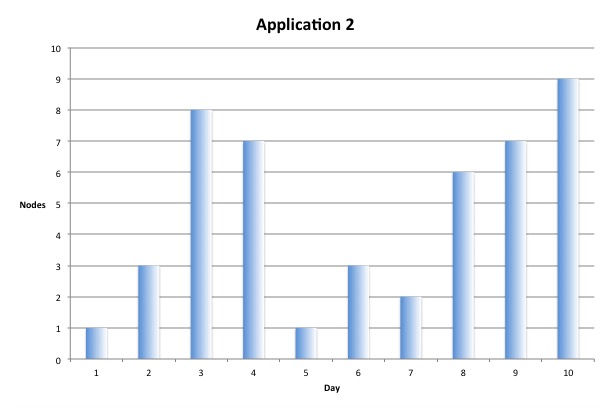
In the figure above we see a timeline of the infrastructure utilisation of a fictional application (Application 2). In a static environment, we need to provision infrastructure for peak load resulting in the utilisation of 20 nodes in total. Let’s now look at the aggregated utilisation.
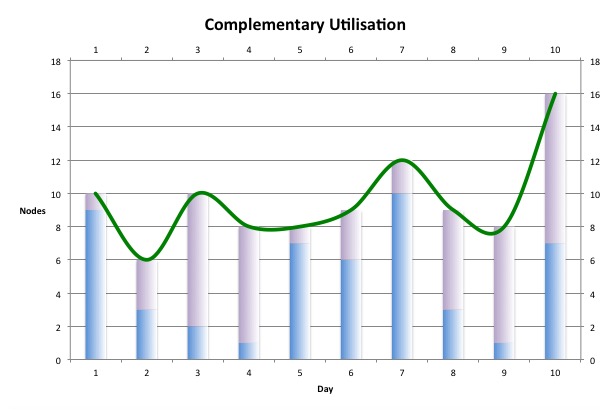
We can see that the aggregate peak load is 17 nodes. In a private shared infrastructure we still need to provision for peak and so can save the cost of 3 nodes. Let’s assume a blended cost per node of $6000 p.a. We will save $18,000 p.a. Depending on the payload you can pretty much achieve these savings in a virtualized environment.
But it gets better. In a public IaaS you do not have to provision for peak load but can provision for current requirement. This means that now, everything above the green line becomes a saving opportunity. With the same cost per node assumptions we can now save $53,400 p.a. These savings can also be increased through meter based licensing, reduced operational costs etc.
The only thing left to ask is that if you are not doing IaaS, why not?